Introducing the Penn Action Dataset
Penn Action Dataset (University of Pennsylvania) contains 2326 video sequences of 15 different actions and human joint annotations for each sequence. The dataset is available for download via the following link:
Download: https://www.cis.upenn.edu/~kostas/Penn_Action.tar.gz
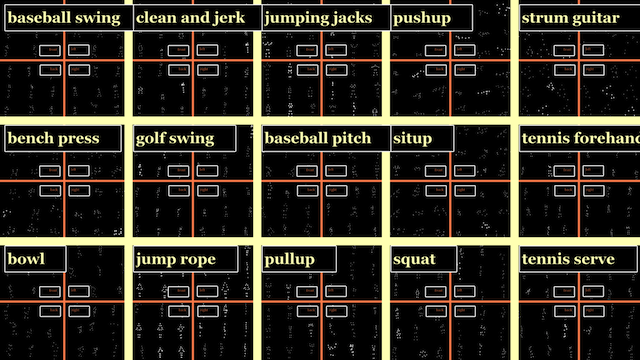
Dataset At a Glance

Reference
If you use our dataset, please cite the following paper:
Weiyu Zhang, Menglong Zhu and Konstantinos Derpanis, "From Actemes to Action:
A Strongly-supervised Representation for Detailed Action Understanding"
International Conference on Computer Vision (ICCV). Dec 2013.
Dataset Content
The dataset is organized in the following format:
/frames ( all image sequences )
/0001
000001.jpg
000002.jpg
...
/0002
...
/labels ( all annotations )
0001.mat
0002.mat
...
/tools ( visualization scripts )
visualize.m
...
The image frames are located in the /frames folder. All frames are in RGB. The resolution of the frames are within the size of 640x480.
The annotations are in the /labels folder. The sequence annotations include class label, coarse viewpoint, human body joints (2D locations and visibility), 2D bounding boxes and training/testing label. Each annotation is a separate MATLAB .mat file under /labels.
An example annotation looks as follows in MATLAB:
annotation =
action: 'tennis_serve'
pose: 'back'
x: [46x13 double]
y: [46x13 double]
visibility: [46x13 logical]
train: 1
bbox: [46x4 double]
dimensions: [272 481 46]
nframes: 46
List of Actions
baseball_pitch clean_and_jerk pull_ups strumming_guitar
baseball_swing golf_swing push_ups tennis_forehand
bench_press jumping_jacks sit_ups tennis_serve
bowling jump_rope squats
List of Annotated Joints
1. head
2. left_shoulder 3. right_shoulder
4. left_elbow 5. right_elbow
6. left_wrist 7. right_wrist
8. left_hip 9. right_hip
10. left_knee 11. right_knee
12. left_ankle 13. right_ankle
Annotation Tools
The annotation tool used in creating this dataset is also available. Please refer to http://dreamdragon.github.io/vatic/ for more details.
Contact
Please direct any questions regarding the dataset to
Kosta Derpanis kosta@yorku.ca
Kostas Daniilidis kostas@cis.upenn.edu
Menglong Zhu http://dreamdragon.github.io